Deploying Multiple Services in Serverless
Over the last few chapters we have looked at how to:
- Link multiple Serverless services using CloudFormation cross-stack references
- Create our DynamoDB table as a Serverless service
- Create an S3 bucket as a Serverless service
- Use the same API Gateway domain and resources across multiple Serverless services
- Create a Serverless service for Cognito to authenticate and authorize our users
All this is available in a sample repo that you can deploy and test.
Now we can finally look at how to deploy our services. The addition of cross-stack references to our services means that we have some built-in dependencies. This means that we need to deploy some services before we deploy certain others.
Service Dependencies
Following is a list of the services we created:
database
uploads
notes
users
auth
And based on our cross-stack references the dependencies look roughly like:
database > notes > users
uploads > auth
notes
Where the a > b symbolizes that service a needs to be deployed before service b. To break it down in detail:
-
The
usersAPI service relies on thenotesAPI service for the API Gateway cross-stack reference. -
The
usersandnotesAPI services rely on thedatabaseservice for the DynamoDB cross-stack reference. -
And the
authservice relies on theuploadsandnotesservice for the S3 bucket and API Gateway cross-stack references respectively.
Hence to deploy all of our services we need to follow this order:
databaseuploadsnotesusersauth
Now there are some intricacies here but that is the general idea.
Multi-Service Deployments
Given the rough dependency graph above, you can script your CI/CD pipeline to ensure that your automatic deployments follow these rules. There are a few ways to simplify this process.
It is very likely that your auth, database, and uploads service don’t change very often. You might also need to follow some strict policies across your team to make sure no haphazard changes are made to it. So by separating out these resources into their own services (like we have done in the past few chapters) you can carry out updates to these services by using a manual approval step as a part of the deployment process. This leaves the API services. These need to be deployed manually once and can later be automated.
Service Dependencies in Seed
Seed has a concept of Deploy Phases to handle service dependencies.
You can configure this by heading to the app settings and hitting Manage Deploy Phases.

Here you’ll notice that by default all the services are deployed concurrently.
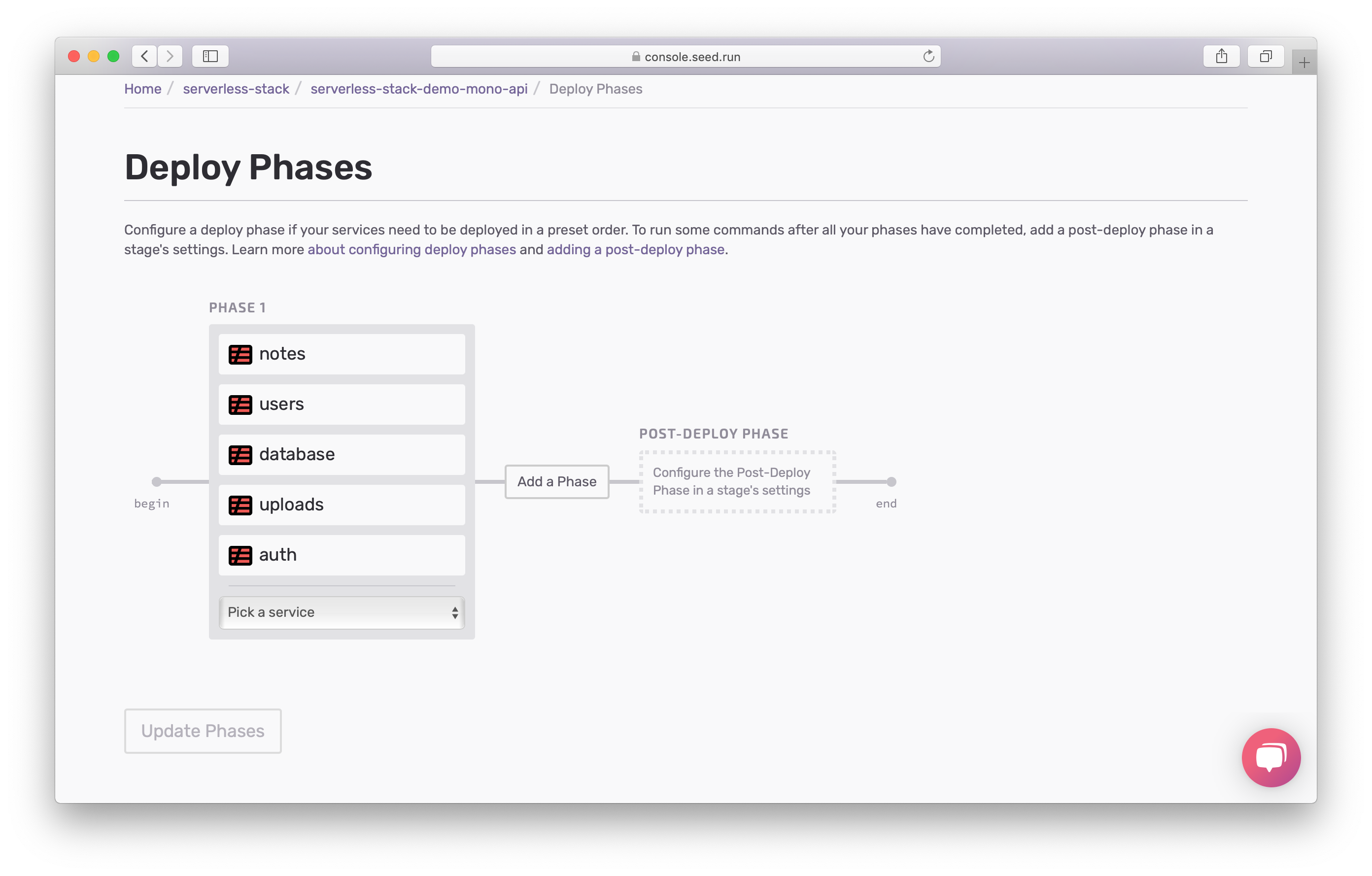
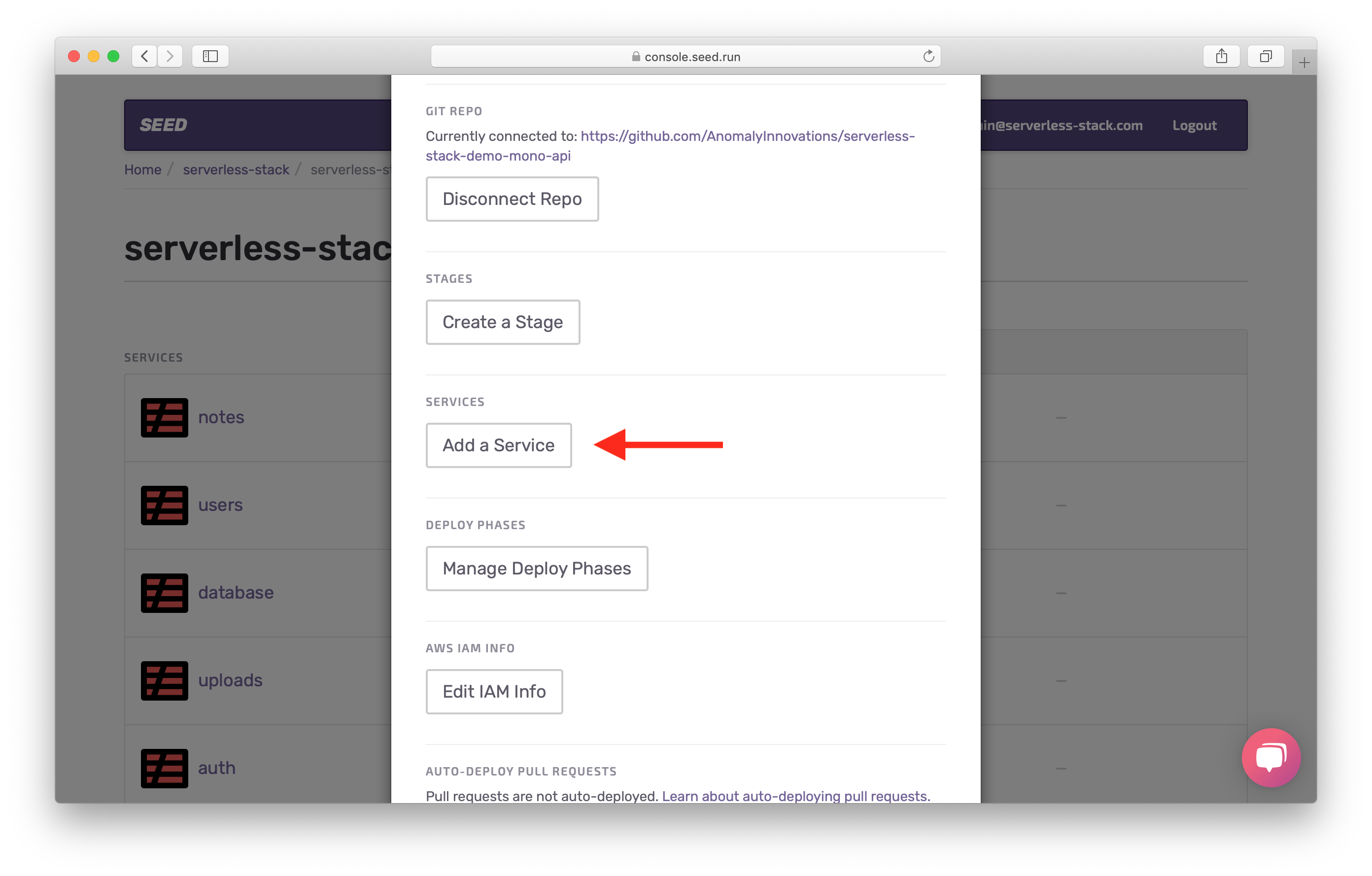
Note that, you’ll need to add your services first. To do this, head over to the app Settings and hit Add a Service.
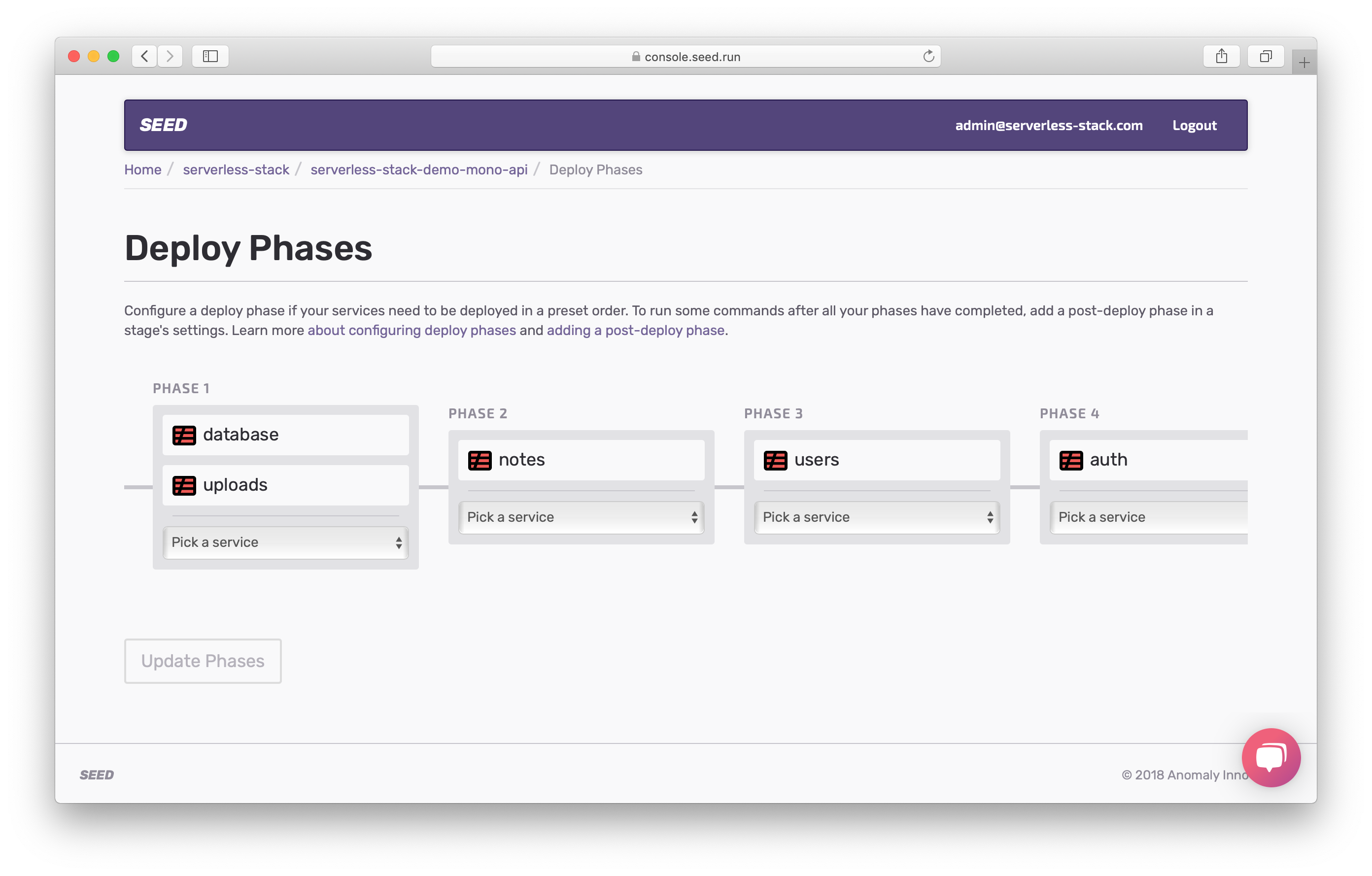
We can configure our service dependencies by adding the necessary deploy phases and moving the services around.
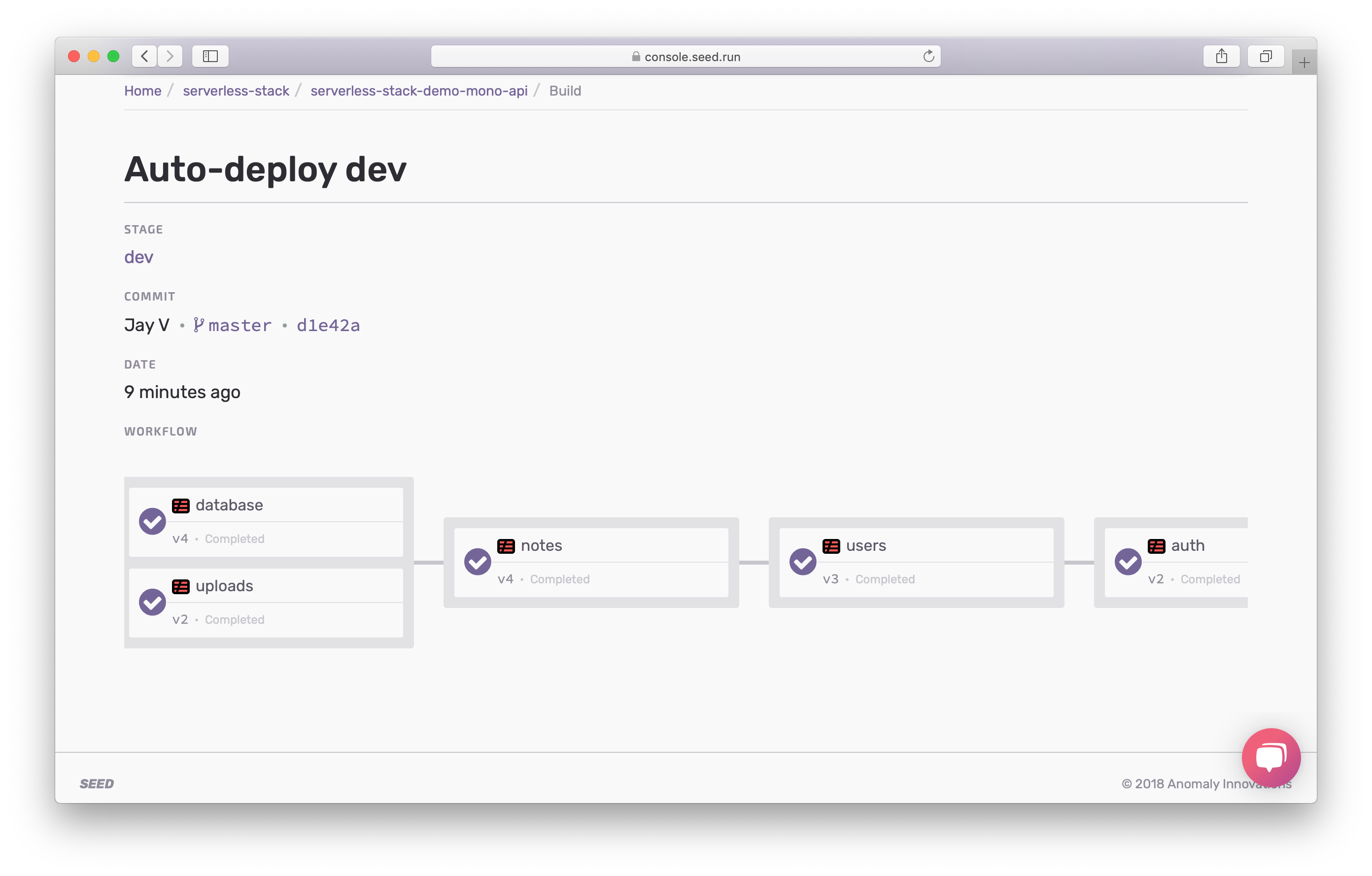
And when you deploy your app, the deployments are carried out according to the deploy phases specified.
Environments
A quick word of handling environments across these services. The services that we have created can be easily re-created for multiple environments or stages. A good standard practice is to have a dev, staging, and prod environment. And it makes sense to replicate all your services across these three environments.
However, when you are working on a new feature or you want to give a developer on your team their own environment, it might not make sense to replicate all of your services across them. It is more common to only replicate the API services as you create multiple dev environments.
Mono-Repo vs Multi-Repo
Finally, when considering how to house these services in your repository, it is worth looking at how much code is shared across them. Typically, your infrastructure services (database, uploads and auth) don’t share any code between them. In fact they probably don’t have any code in them to begin with. These services can be put in their own repos. Whereas the API services that might share some code (request and response handling) can be placed in the same repo and follow the mono-repo approach outlined in the Organizing Serverless Projects chapter.
This combined way of using the multi-repo and mono-repo strategy also makes sense when you think about how we deploy them. As we stated above, the infrastructure services are probably going to be deployed manually and with caution. While the API services can be automated (using Seed or your own CI) for the mono-repo services and handle the others ones as a special case.
Conclusion
Hopefully these series of chapters have given you a sense of how to structure large Serverless applications using CloudFormation cross-stack references. And the example repo gives you a clear working demonstration of the concepts we’ve covered. Give the above setup a try and leave us your feedback in the comments.
For help and discussion
Comments on this chapterFor reference, here is the code we are using
Mono-repo Backend SourceIf you liked this post, please subscribe to our newsletter, give us a star on GitHub, and follow us on Twitter.
Brought to you by
